
In today’s data-driven world, managing how data moves across systems is just as important as the data itself. Microsoft Fabric, the all-in-one data platform, brings powerful tools for building and orchestrating end-to-end data workflows at scale. In this post, we’ll walk through what data orchestration means in Fabric, how Fabric Pipelines work, and how you can use them to automate complex data tasks with minimal effort.
💡 What is Data Orchestration?
Data orchestration is the process of coordinating and automating the movement and transformation of data across systems. Whether you’re pulling data from cloud storage, transforming it, or loading it into a warehouse — orchestration ensures the right data reaches the right place at the right time, reliably.
In Microsoft Fabric, orchestration is powered by Data Pipelines, similar in concept to Azure Data Factory pipelines but natively integrated with the Fabric ecosystem.
🚀 Why Use Microsoft Fabric for Data Orchestration?
Here are a few reasons to use Microsoft Fabric Pipelines:
- ✅ Unified Experience: Build, monitor, and manage pipelines alongside your lakehouse, data warehouse, and Power BI projects.
- 🔄 Scheduled & Event-Based Triggers: Automate your data flows with time-based or event-driven triggers.
- 🧱 Drag-and-Drop UI: Low-code visual designer to quickly build pipelines.
- 🔗 Built-In Connectors: Native support for OneLake, SQL databases, APIs, Blob storage, and more.
- 📈 Monitoring Tools: Track pipeline runs and troubleshoot with ease.
🔧 Getting Started: Building a Simple Pipeline in Fabric
Let’s look at a simple example: moving data from Azure Blob Storage to a Fabric Lakehouse and then triggering a notebook for transformation.
Step 1: Open a Data Pipeline
- Go to your Microsoft Fabric workspace.
- Click + New > Data Pipeline.
- Give it a meaningful name, like
BlobToLakehousePipeline.
Understand pipelines
Pipelines in Microsoft Fabric encapsulate a sequence of activities that perform data movement and processing tasks. You can use a pipeline to define data transfer and transformation activities, and orchestrate these activities through control flow activities that manage branching, looping, and other typical processing logic. The graphical pipeline canvas in the Fabric user interface enables you to build complex pipelines with minimal or no coding required.
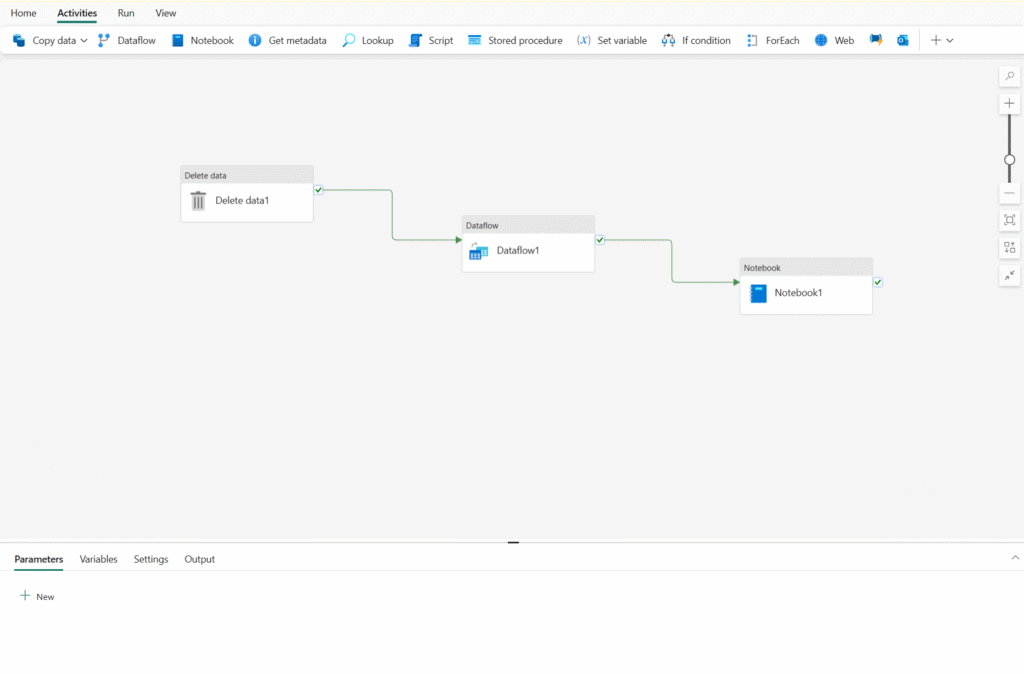
Core pipeline concepts
Before building pipelines in Microsoft Fabric, you should understand a few core concepts.
Activities
Activities are the executable tasks in a pipeline. You can define a flow of activities by connecting them in a sequence. The outcome of a particular activity (success, failure, or completion) can be used to direct the flow to the next activity in the sequence.
There are two broad categories of activity in a pipeline.
- Data transformation activities – activities that encapsulate data transfer operations, including simple Copy Data activities that extract data from a source and load it to a destination, and more complex Data Flow activities that encapsulate dataflows (Gen2) that apply transformations to the data as it is transferred. Other data transformation activities include Notebook activities to run a Spark notebook, Stored procedure activities to run SQL code, Delete data activities to delete existing data, and others. In OneLake, you can configure the destination to a lakehouse, warehouse, SQL database, or other options.
- Control flow activities – activities that you can use to implement loops, conditional branching, or manage variable and parameter values. The wide range of control flow activities enables you to implement complex pipeline logic to orchestrate data ingestion and transformation flow.
Parameters
Pipelines can be parameterized, enabling you to provide specific values to be used each time a pipeline is run. For example, you might want to use a pipeline to save ingested data in a folder, but have the flexibility to specify a folder name each time the pipeline is run.
Using parameters increases the reusability of your pipelines, enabling you to create flexible data ingestion and transformation processes.
Pipeline runs
Each time a pipeline is executed, a data pipeline run is initiated. Runs can be initiated on-demand in the Fabric user interface or scheduled to start at a specific frequency. Use the unique run ID to review run details to confirm they completed successfully and investigate the specific settings used for each execution.
Step 2: Add Copy Data Activity
- Drag the Copy Data activity onto the canvas.
- Configure Source: Connect to your Azure Blob container.
- Configure Destination: Select your Lakehouse table or file location in OneLake.
Step 3: Add a Notebook Activity (Optional)
- Use a Notebook Activity to perform transformations.
- Link to a Fabric Notebook that cleans or aggregates the data.
Step 4: Add a Trigger
- Create a Schedule Trigger (e.g., daily at 3 AM) or use Event-Based Triggers for real-time movement.
Step 5: Publish and Run
- Validate your pipeline.
- Click Publish, then Run to test it out.
- Monitor the results in the Pipeline Monitoring tab.
🧠 Best Practices for Fabric Pipelines
- Modular Design: Break larger workflows into smaller pipelines for better manageability.
- Error Handling: Use If Condition and Set Variable activities for custom retry logic and alerts.
- Logging: Send success/failure logs to a centralized monitoring location.
- Versioning: Maintain pipeline versions and document changes for collaboration.
🌐 Real-World Use Cases
- 🔄 ETL for Reporting: Extract raw data, clean with notebooks, and load into Power BI models.
- 🛠️ Data Engineering Automation: Run nightly jobs that process IoT sensor data or CRM updates.
- 🧾 Data Compliance Pipelines: Audit, transform, and archive sensitive data using automated rules.
📌 Final Thoughts
Microsoft Fabric Pipelines provide a seamless way to automate your data movement and transformation processes without leaving the Fabric ecosystem. Whether you’re building simple copy flows or complex multi-stage pipelines, Fabric gives you the tools to orchestrate with confidence, at scale.
Start small. Think big. Automate everything.
The article walks through a real-world example of moving data from Azure Blob Storage into a Fabric Lakehouse and transforming it using notebooks, all within a single automated pipeline. It also shares best practices, real-world use cases across industries, and practical tips for implementation.
For organizations looking to streamline their data processes, Fabric Pipelines offer a low-code, scalable, and deeply integrated solution—empowering faster insights and more reliable data delivery.
Happy Reading!
In it something is. It is grateful to you for the help in this question. I did not know it.