Data Engineering in Microsoft Fabric
Microsoft Fabric, also known as Azure Data Factory, is a cloud-based data integration service that allows you to create, schedule, and manage data pipelines. As a part of data engineering in Microsoft Fabric, you can perform various tasks related to data ingestion, transformation, and movement.
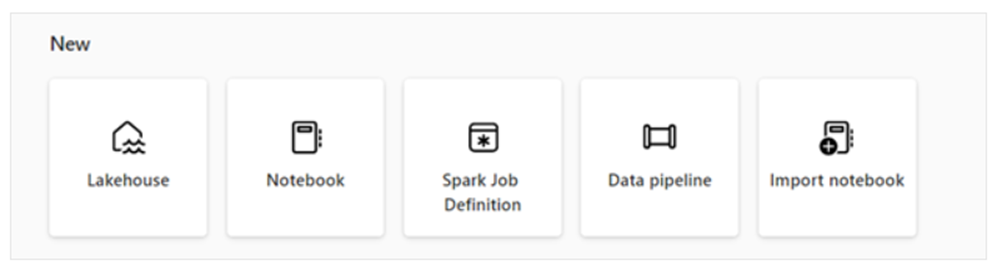
- • Create and manage your data using a Lakehouse
- • Design pipelines to copy data into your Lakehouse
- • Use Spark job definitions to submit batch/streaming job to Spark cluster
- Use notebooks to write code for data ingestion, preparation, and transformation
Key Components and Features:
- Data Movement: Using Azure Data Factory, you can move data seamlessly and efficiently from various on-premises and cloud data sources to Azure. This includes support for relational databases, non-relational data stores, file systems, and more.
- Data Transformation: The platform provides the capability to transform raw data into a usable format for analysis and reporting. This involves data mapping, cleansing, aggregation, and other transformation processes.
- Data Orchestration: With Azure Data Factory, you can orchestrate and coordinate data workflows, ensuring that data is processed in the right order and at the right time.
- Integration with Other Azure Services: Microsoft Fabric integrates with other Azure services such as Azure Synapse Analytics, Azure Databricks, and Azure HDInsight, allowing you to leverage additional capabilities for advanced analytics and machine learning.
- Monitoring and Management: The platform offers monitoring and management features to track the performance and health of data pipelines, as well as the ability to troubleshoot issues as they arise.
Advantages of Using Microsoft Fabric for Data Engineering:
- Scalability: Azure Data Factory can handle large-scale data engineering tasks, making it suitable for enterprises with diverse and voluminous data requirements.
- Integration: Seamless integration with other Azure services provides a comprehensive environment for end-to-end data engineering and analytics.
- Hybrid Capabilities: Fabric supports hybrid data integration, enabling organizations to work with both on-premises and cloud-based data sources.
- Security and Compliance: The platform offers robust security measures and compliance certifications, ensuring that sensitive data is handled in a secure and compliant manner.
In conclusion, data engineering in Microsoft Fabric (Azure Data Factory) empowers organizations to build, deploy, and manage data pipelines for diverse data integration and transformation needs, leveraging the capabilities of the Azure cloud platform to drive valuable insights and innovation.
Case Study: Retail Sales with Data Engineering
Company Background: XYZ Retail is a multinational retail chain with stores across the globe. They sell a wide range of products, including electronics, clothing, groceries, and more. XYZ Retail wants to leverage data engineering to gain insights into their sales, customer behavior, inventory management, and supply chain operations.
Objective: The objective is to build a comprehensive analytics platform using Azure Synapse Analytics to analyze sales data, optimize inventory levels, improve customer experience, and enhance overall business performance.
Solution:
- Data Ingestion:
- Utilizing Azure Data Factory, XYZ Retail sets up data pipelines to ingest sales data from various sources, including POS systems in stores, online transactions, and external vendors.
- Data from different sources is standardized, cleansed, and stored in Azure Blob Storage and Azure SQL Database for further processing.
- Data Transformation:
- Azure Synapse Analytics is used to transform raw sales data into actionable insights. Spark pools are leveraged for processing large volumes of data in parallel.
- Data engineers write Spark jobs and SQL queries to perform data cleansing, aggregation, and enrichment. For example, they aggregate sales data by product category, location, and time.
- Data Storage:
- Azure Synapse Analytics provides a unified platform for storing both structured and unstructured data. XYZ Retail stores process sales data in a dedicated SQL Data Warehouse within Azure Synapse.
- They also utilize Azure Data Lake Storage Gen2 for storing raw data, enabling data scientists to perform advanced analytics and machine learning.
- Data Analysis:
- Data analysts and business users access the analytics platform through tools like Power BI and Azure Synapse Studio.
- They create interactive dashboards and reports to visualize sales trends, customer demographics, product performance, and inventory levels.
- Advanced analytics techniques, such as predictive modeling and forecasting, are applied to optimize inventory management and identify potential sales opportunities.
- Data Integration:
- Integration with Azure Machine Learning enables XYZ Retail to build predictive models for demand forecasting, customer segmentation, and personalized recommendations.
- Azure Synapse seamlessly integrates with Power BI for real-time analytics and reporting, empowering decision-makers with actionable insights.
- Security and Compliance:
- XYZ Retail ensures data security and compliance with Azure Synapse’s built-in security features such as encryption, RBAC, and auditing.
- They adhere to regulatory requirements such as GDPR and PCI-DSS to protect customer data and maintain trust.
Microsoft Fabric:

Enabling Microsoft Fabric
Microsoft Fabric shares the same Power BI tenant. If you have a Power BI or Microsoft Fabric tenant already created: Enable fabric at the tenant level: If you have admin privileges, you can access the admin center from the Settings menu in the upper right corner of the Power BI service. From here, you can enable Fabric on the tenant settings page. When you enable Microsoft Fabric using the tenant setting, users can create Fabric items in that tenant. For that, navigate to the tenant settings page in the admin portal page of the tenant, expand the Users can create fabric items field, toggle the switch to enable or disable it, and then hit Apply.

Create and explore a lake house
- We create and configure a new lakehouse in the data engineering workload. Each lake house produces three named items in the fabric-enabled workspace:
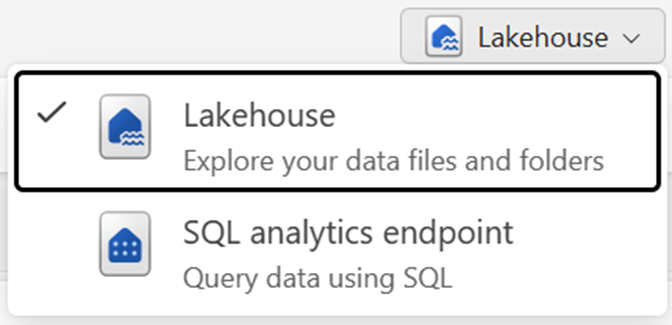
- Lakehouse is the lake house storage and metadata, where you interact with files, folders, and table data.
- The semantic model (default) is an automatically created semantic model based on the tables in the lake house. Power BI reports can be built from the semantic model.
- The SQL analytics endpoint is a read-only SQL analytics endpoint through which you can connect and query data with Transact-SQL.
Ingest data into a lake house
- There are many ways to load data into a Fabric lake house:
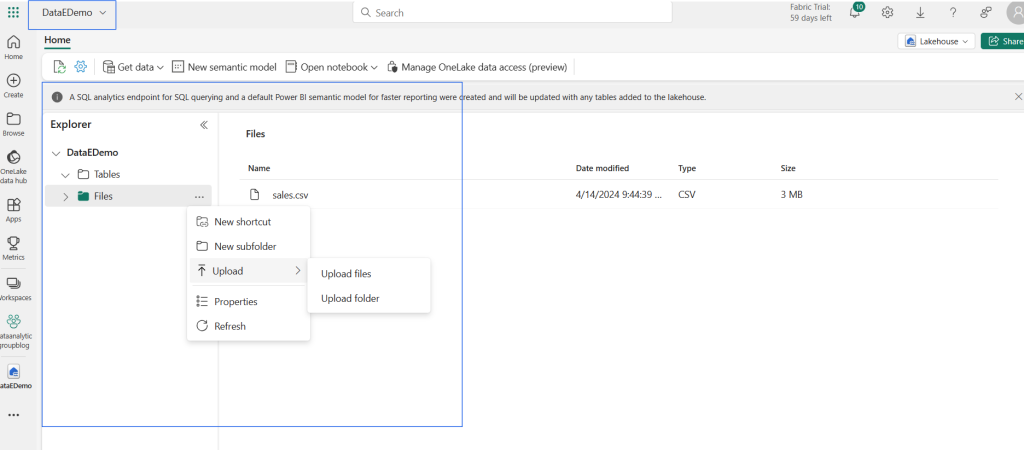
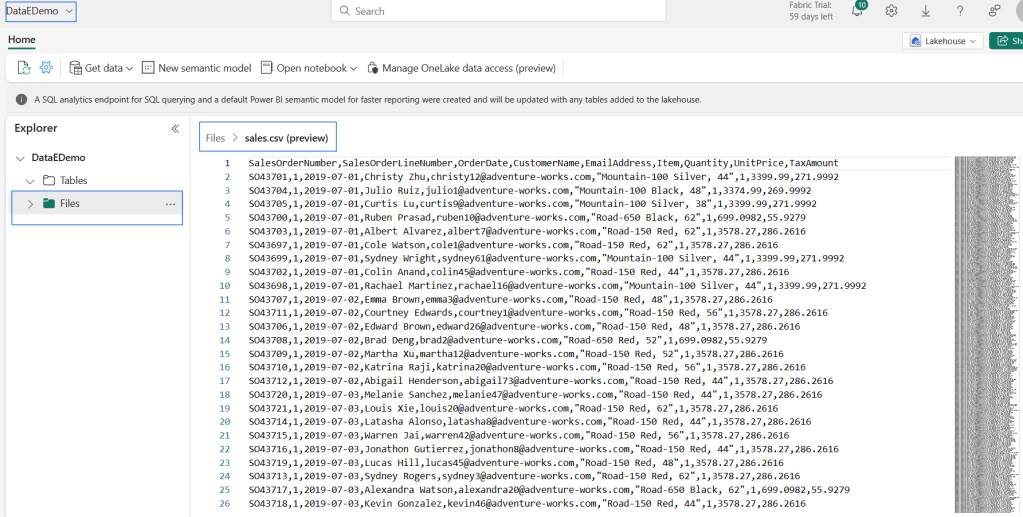
- Upload: Upload local files or folders to the lake house. You can then explore and process the file data and load the results into tables.
- • Dataflows (Gen2): Import and transform data from a range of sources using Power Query Online and load it directly into a table in the lake house.
- •Notebooks: Use notebooks in Fabric to ingest and transform data and load it into tables or files in the lake house.
- • Data Factory pipelines: Copy data and orchestrate data processing activities, loading the results into tables or files in the lake house.
- Shortcuts are useful when you need to source data that’s in a different/external storage account or even a different cloud provider. Within your Lakehouse you can create shortcuts that point to different storage accounts and other Fabric items like data warehouses, KQL databases, and other Lake houses.
Working with Data Lakes and External Tools
- Data sources: Fabric makes it quick and easy to connect to Azure Data Services, as well as other cloud-based platforms and on-premises data sources, for streamlined data ingestion.
- Ingestion: You can quickly build insights for your organization using more than 200 native connectors. These connectors are integrated into the Fabric pipeline
- drag-and-drop data transformation with dataflow..
- Transform and store: Fabric standardizes on Delta Lake format. Which means all the Fabric engines can access and manipulate the same dataset stored in One Lake without duplicating data. This storage system provides the flexibility to build lake houses using a medallion architecture or a data mesh, depending on your organizational requirement.
- Consume: Power BI can consume data from the Lakehouse for reporting and visualization

Demo
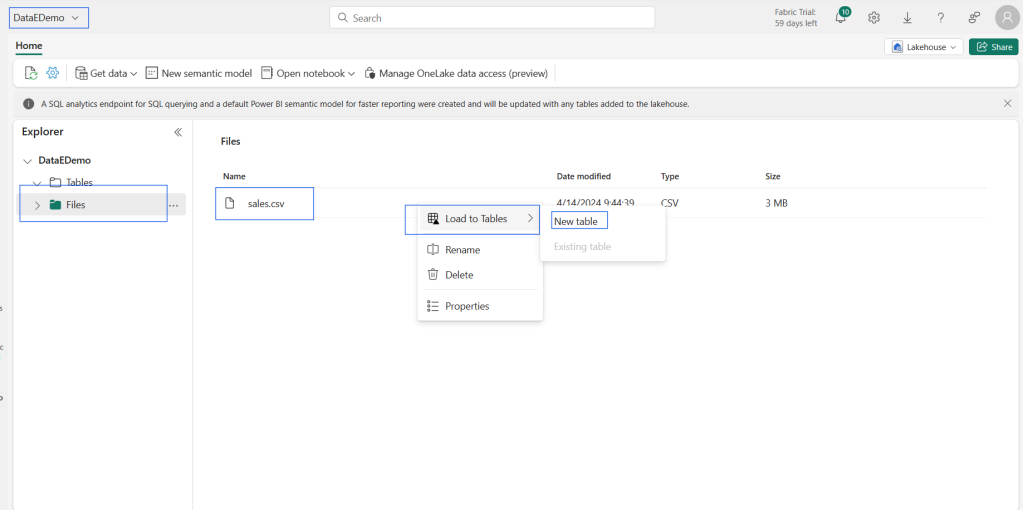

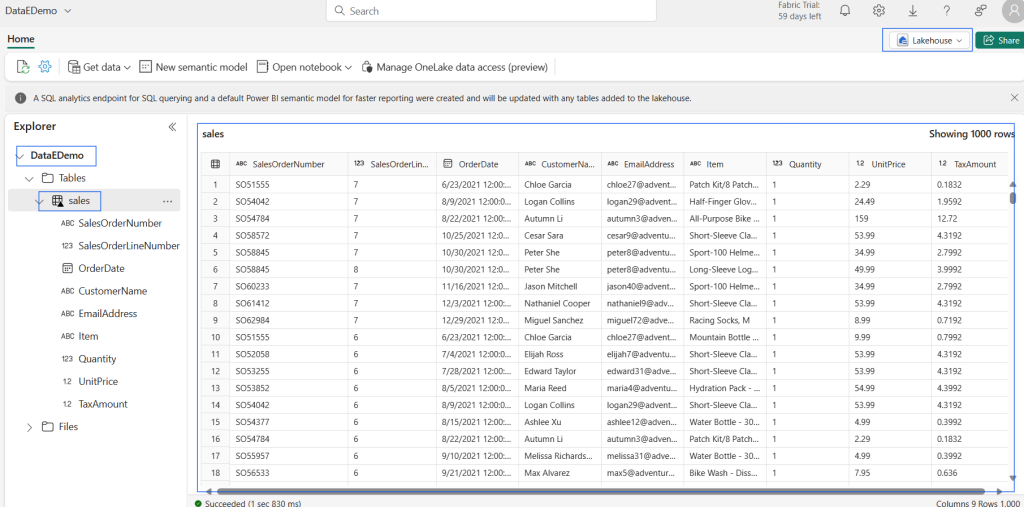

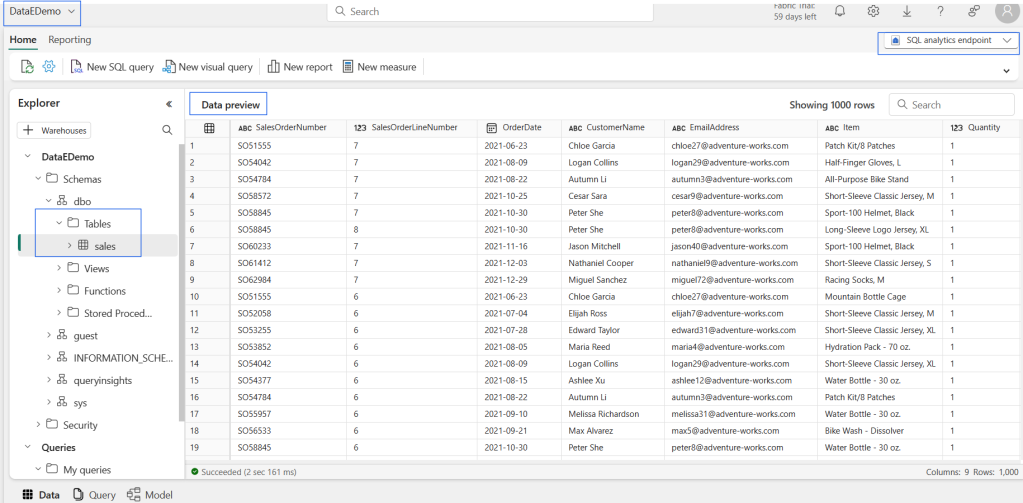
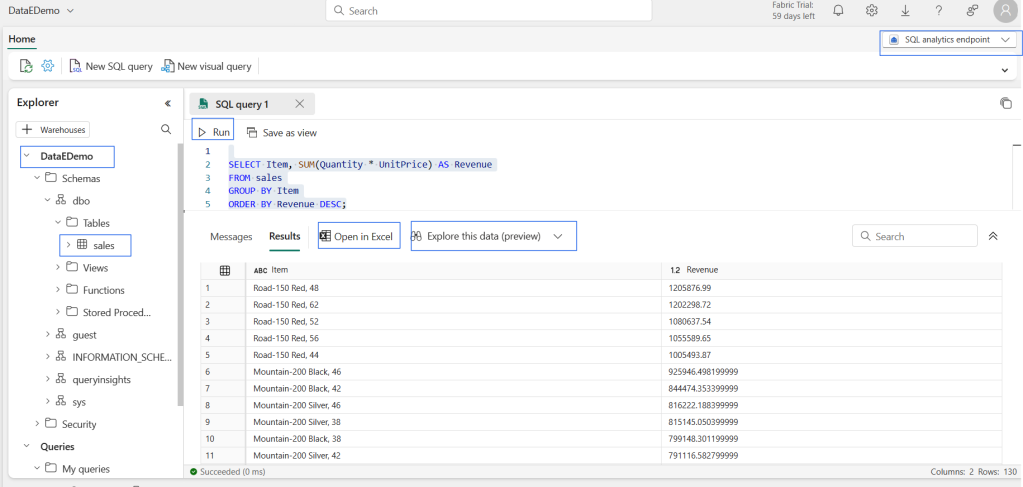


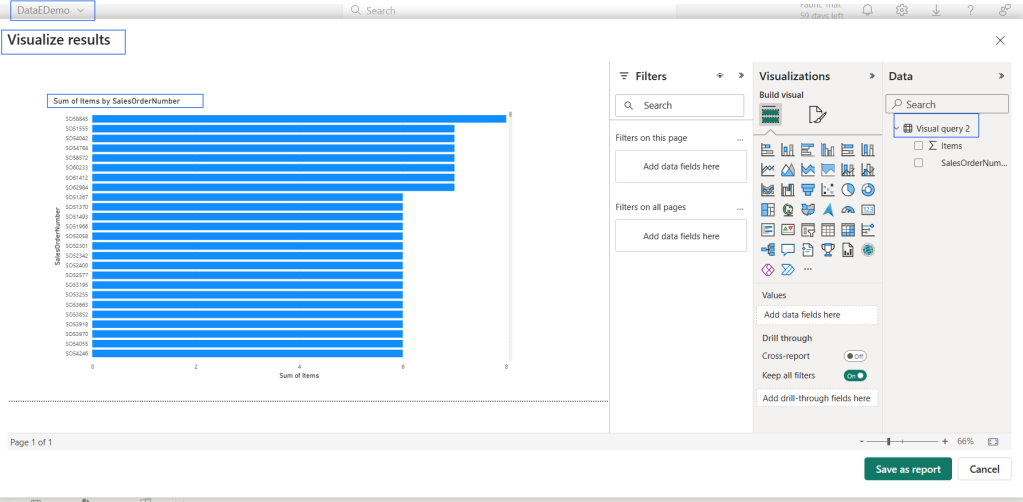

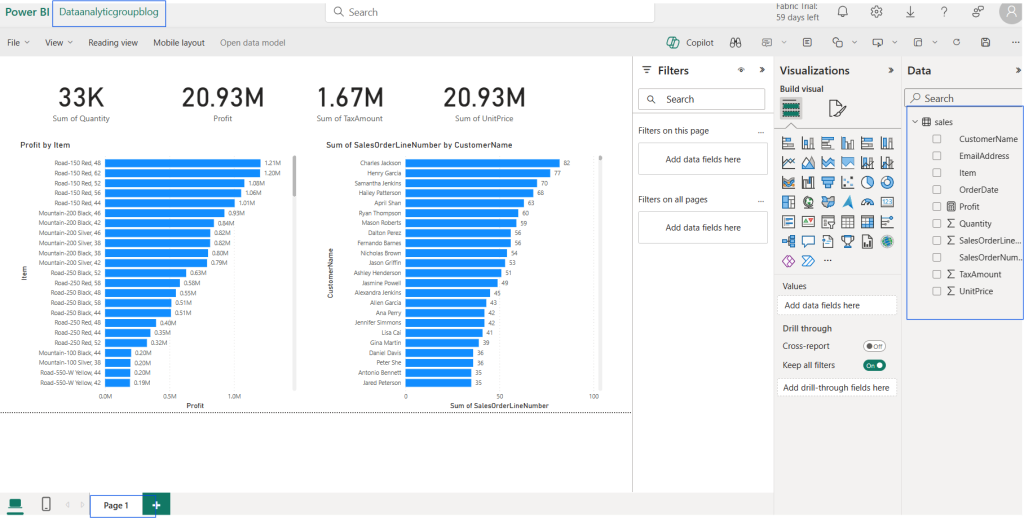
Conclusion
Microsoft Fabric is a powerful tool for data engineering, providing a comprehensive suite of services and capabilities for data collection, storage, processing, and analysis. Whether you’re looking to implement a Lakehouse or data warehouse architecture, or a combination of both, Fabric offers the flexibility and functionality to meet your data engineering needs.
Please share your valuable feedback!!
Thank you
